这篇文章不会专注来讲 JVM 的某个实现的 JIT 技术,而是介绍一些通用的 JIT 技术及优化方式,字节码与 IR 的区别,以及编译器相关的一些知识,主要目的是为了拓宽一下对语言的理解。本文从 Notion 导出,原本有些代码或注释着色的地方无法在 Markdown 中展示。
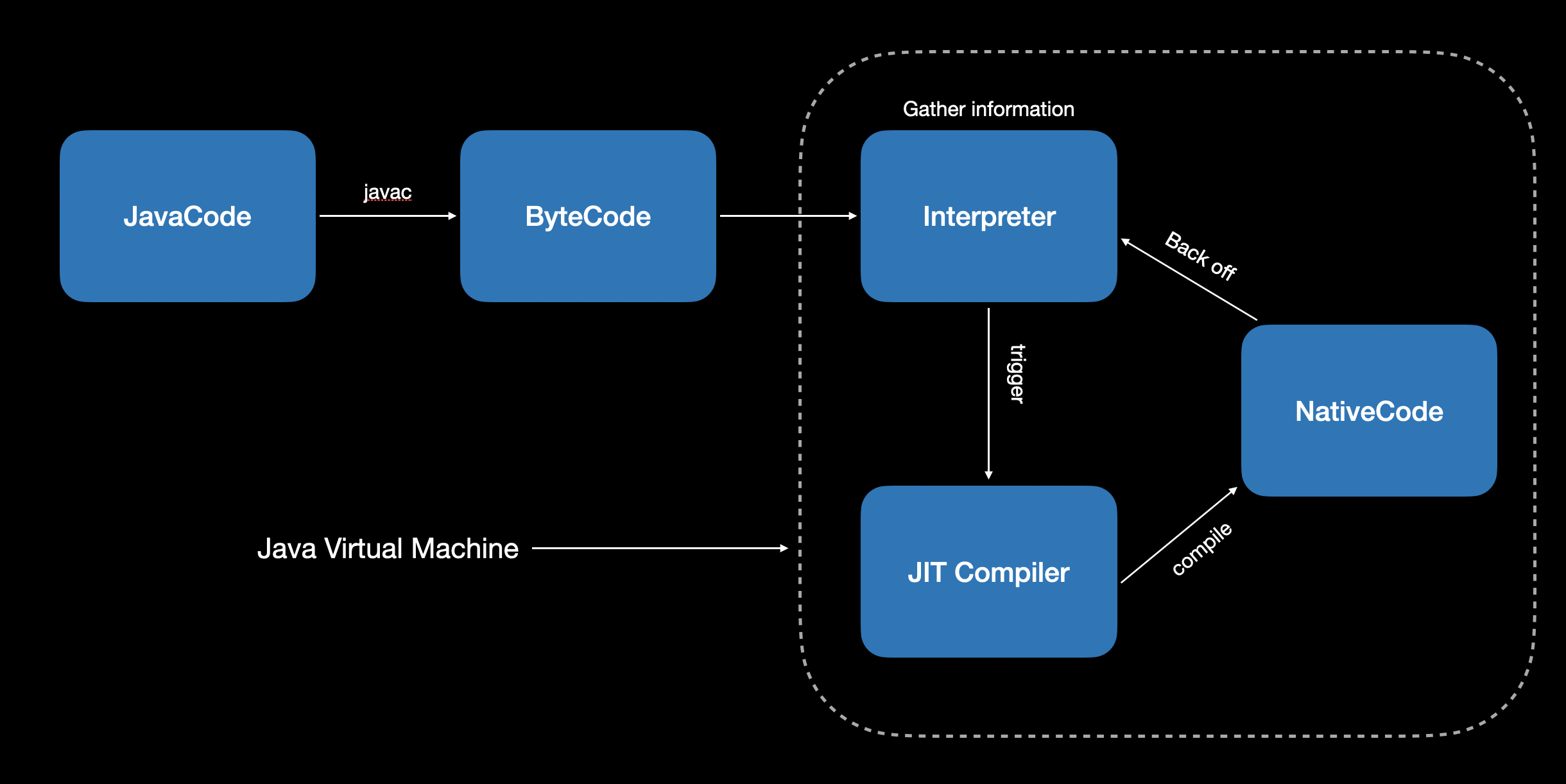
1. JVM 1.1 How it works 一个大概的流程是 Java 代码通过 javac 编译成 bytecode,在 JVM 中解释运行字节码的同时,收集运行时数据,例如每个方法执行的次数,当执行次数超过一定阈值后,会触发 JIT 编译器讲对应的代码段编译为 native code 运行。当编译为 native code 运行后发现调用次数相比以前没有频繁触发了,有可能会回退到解释执行。整个流程如下图。
另一个例子是 Python 语言,Python 常见的一个实现是 CPython,会有一个默认的解释器,但是没有JIT,所以一般情况下 Python 都是解释执行。当然 Python 也有一些其他实现带有 JIT 的,例如 PyPy 等,带 JIT 的性能会至少有一倍以上的提升。
1.2 Do what 在这期间JVM与JIT主要做两个事情,一个是Optimization,一个Inlining,都是为了跑的更快一些。
1.3 AOT 先编译成 native code,然后在运行,由于没有运行时 Profiling,所以编译出来 native code 质量不如 JIT 阶段,性能上不如 JIT。
2. ByteCode Bytecode , also termed portable code or p-code, is a form of instruction set designed for efficient execution by a software interpreter(专门为解释器设计的一种可以高效执行的一种IR ),所谓 IR 就是一种数据结构或者代码,对编译器或者虚拟机来讲相当于 source code。
2.1 What 从一个 Hello World 的例子开始看,先介绍一些字节码指令
getstatic/putstatic: static field access
ldc: load constant value on stack
invokevirtual: call a concrete instance method
return: return from void method
下面是 Kotlin 的例子
1 2 3 fun main () println("hello world" ) }
下面是编译后的字节码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public final static main () V L0 LINENUMBER 2 L0 LDC "hello world" ASTORE 0 L1 ICONST_0 ISTORE 1 L2 GETSTATIC java/lang/System.out : Ljava/io/PrintStream; ALOAD 0 INVOKEVIRTUAL java/io/PrintStream.println (Ljava/lang/Object;)V L3 L4 LINENUMBER 3 L4 RETURN L5 MAXSTACK = 2 MAXLOCALS = 2
2.2 Why need bytecode
屏蔽平台差异(32/64位,int 范围,线程实现等)
bytecode作为一种 IR 对编译器和虚拟机友好
3. JIT Compiler 这一步需要加一些 vm 的参数,打开 JIT 相关的 log
-Xbatch
turn off parallel compilation in background
XX:-TieredCompilation
disable tieredCompilation avoid some nising
-XX:+PrintCompilation
display method as they compile
-XX:+PrintInlining(XX:+UnlockDiagnosticVMOptions)
display inline method as nested
3.1 Hotsopt JIT
code is interpreted first
after some threshold, JIT fires
numbers of calls
loop for certain time
older hotsopt went straight to “client” to “server”
client do some short test and produce pretty good native code not very optimized but quickly
server gather more information produce much more better native code
tiered compiler goes to “client + profiling” and later server
in this test, we will disable tiered compilation avoid some noising
JIT 的过程分四步,第一步是先解释执行字节码,第二步某些方法执行次数经过一定阈值后 JIT 会介入。旧的虚拟机会有 client 和 server 的区别,client 负责轻度的编译优化速度快,server 会在运行时搜集相关的信息,做一些耗时比较久的编译优化。如下图所示,Server VM 就是前面所说的 server,最后的 mixed mode 表示 JIT 是 interpreted + compile 的混合模式。
当然也可以通过参数将调整 JIT 模式,如下,分别是强制使用编译模式和只解释执行模式
现在的分层编译在原来单一的 client+server 模式上做了更详细划分,C1 就是一个 Client,C2 则是 Server,JVM 中的分层编译具体可以参考 advancedThresholdPolicy 中的注释,这里摘抄一小部分注释稍微解释一下分层编译:
level 0 - interpreter
level 1 - C1 with full optimization (no profiling)
level 2 - C1 with invocation and backedge counters
level 3 - C1 with full profiling (level 2 + MDO)
level 4 - C2
3.2 Compile Optimization
最常见的一种编译期优化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 fun a (x:Int ) Int { return if (x == 0 ) x else x - 1 } fun test (x1: Int , x2: Int , x3: Int ) val s = a(x1) + a(x2) + a(x3) println(s) } fun test (x1: Int , x2: Int , x3: Int ) var var10000 = if (x1 == 0 ) x1 else x1 - 1 var10000 += if (x2 == 0 ) x2 else x2 - 1 val s = var10000 + if (x3 == 0 ) x3 else x3 - 1 println(s) }
1 2 3 4 5 6 7 8 9 10 var y = 1 y = 2 val x = yprintln(x) val y1 = 1 val y2 = 2 val x1 = y2
从 Java 9 开始引入了新的 Graal 编译器代替旧的 C2,旧的几乎由 C++ 编写,维护难度和历史问题都没办法解决,新的则由 Java 编写,实际上 Graal 是一个由 Java 编写的虚拟机。
需要说明的是所有的 profiling + compilation 工作都是在异步线程执行的
下面看一个具体的例子Sample:
1 2 3 4 5 6 7 8 9 fun main () for (i in 0. .100000 ) { hello() } } private fun hello () print("" ) }
Key
Desc
Reference
A1 column
since start time
sources
B1 column
compilation number
sources
C1 column
class name method name byte code size
sources
b
Blocking compiler (always set for client)
sources
*
Generating a native wrapper
%
On stack replacement (where the compiled code is running)
sources
!
Method has exception handlers(try catch)
sources
s
Method declared as synchronized
sources
n
Method declared as native
sources
m
monitors(synchronized)
sources
made not entrant
compilation was wrong/incomplete no future callers will use this version
made zombie
code is not in use and ready for GC
下面是 JIT 的 log, A1 这列表示 JIT 执行的时间,起点是 JVM 启动开始计算,B1 这列表示编译的 index,代表这个方法是第几个被编译的, C1 这列是被编译的方法。中间的注释表示中间经过了几次println
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 A1 B1 C1 94 1 b java.lang.String::equals (81 bytes)94 2 b java.lang.String::hashCode (55 bytes)96 3 b java.lang.String::indexOf (70 bytes)98 4 b sun.nio.cs.UTF_8$Encoder::encode (359 bytes)106 5 b java.util.Properties$LineReader::readLine (468 bytes)118 6 b java.nio.Buffer::position (5 bytes)118 7 b java.nio.ByteBuffer::arrayOffset (35 bytes)118 8 b sun.nio.cs.UTF_8$Encoder::encodeArrayLoop (489 bytes)127 9 b java.nio.Buffer::position (43 bytes)127 10 n java.lang.System::arraycopy (native) (static)130 11 b java.lang.Object::<init > (1 bytes)135 12 b java.nio.Buffer::limit (5 bytes)136 13 b java.nio.charset.CoderResult::isUnderflow (13 bytes)136 14 b java.io.BufferedWriter::ensureOpen (18 bytes)136 15 b java.io.PrintStream::ensureOpen (18 bytes)137 16 !b java.io.BufferedWriter::write (117 bytes)147 17 s b java.io.BufferedOutputStream::flush (12 bytes)149 18 b java.io.BufferedOutputStream::flushBuffer (29 bytes)149 19 b java.io.OutputStream::flush (1 bytes)152 20 b java.lang.String::length (6 bytes)152 21 b java.nio.ByteBuffer::array (35 bytes)163 22 b java.nio.Buffer::limit (62 bytes)163 23 b java.nio.Buffer::flip (20 bytes)164 24 b java.nio.Buffer::<init > (121 bytes)164 25 b java.nio.Buffer::clear (20 bytes)165 26 b java.nio.Buffer::hasRemaining (17 bytes)165 27 b java.nio.CharBuffer::hasArray (20 bytes)165 28 b java.nio.ByteBuffer::hasArray (20 bytes)166 29 b java.nio.charset.CoderResult::isOverflow (14 bytes)166 30 b java.nio.Buffer::remaining (10 bytes)166 31 b java.nio.CharBuffer::<init > (22 bytes)167 32 !b java.nio.CharBuffer::wrap (20 bytes)168 33 b java.nio.HeapCharBuffer::<init > (14 bytes)169 34 n java.io.FileOutputStream::writeBytes (native) 169 35 b java.io.Writer::write (11 bytes)170 36 !b java.io.BufferedWriter::flushBuffer (53 bytes)177 37 b java.io.OutputStreamWriter::write (11 bytes)181 38 !b sun.nio.cs.StreamEncoder::write (78 bytes)187 39 b sun.nio.cs.StreamEncoder::ensureOpen (18 bytes)187 40 b sun.nio.cs.StreamEncoder::implWrite (156 bytes)191 41 !b java.nio.charset.CharsetEncoder::encode (285 bytes)192 42 b sun.nio.cs.UTF_8$Encoder::encodeLoop (28 bytes)193 43 b java.io.OutputStreamWriter::flushBuffer (8 bytes)200 44 !b sun.nio.cs.StreamEncoder::flushBuffer (42 bytes)207 45 b sun.nio.cs.StreamEncoder::isOpen (5 bytes)207 46 b sun.nio.cs.StreamEncoder::implFlushBuffer (15 bytes)212 47 b sun.nio.cs.StreamEncoder::writeBytes (132 bytes)219 48 !b java.io.PrintStream::write (69 bytes)223 49 s b java.io.BufferedOutputStream::write (67 bytes)237 50 b java.lang.String::indexOf (7 bytes)240 51 b java.lang.String::valueOf (14 bytes)241 52 b TestKt::hello (13 bytes)247 53 !b java.io.PrintStream::println (31 bytes)255 54 b java.io.PrintStream::print (13 bytes)258 55 !b java.io.PrintStream::write (83 bytes)262 56 !b java.io.PrintStream::newLine (73 bytes)265 57 b java.io.BufferedWriter::newLine (9 bytes)275 58 % b TestKt::main @ 5 (20 bytes)457 58 % TestKt::main @ -2 (20 bytes) made not entrant
With Inline Compilation
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 A1 B1 C1 108 1 b java.lang.String::equals (81 bytes)108 2 b java.lang.String::hashCode (55 bytes)109 3 b java.lang.String::indexOf (70 bytes)111 4 b sun.nio.cs.UTF_8$Encoder::encode (359 bytes) @ 14 java.lang.Math::min (11 bytes) (intrinsic) ** 118 5 b java.util.Properties$LineReader::readLine (468 bytes)** @ 48 java.io.Reader::read (9 bytes) never executed @ 62 java.io.FilterInputStream::read (9 bytes) executed < MinInliningThreshold times \-> TypeProfile (5 /5 counts) = java/io/BufferedInputStream @ 311 java.lang.System::arraycopy (0 bytes) (intrinsic) ** 128 6 b java.nio.Buffer::position (5 bytes)** 129 7 b java.nio.ByteBuffer::arrayOffset (35 bytes)** 129 8 b sun.nio.cs.UTF_8$Encoder::encodeArrayLoop (489 bytes) @ 1 java.nio.CharBuffer::array (35 bytes) inline (hot) @ 6 java.nio.CharBuffer::arrayOffset (35 bytes) inline (hot) @ 10 java.nio.Buffer::position (5 bytes) accessor @ 17 java.nio.CharBuffer::arrayOffset (35 bytes) inline (hot) @ 21 java.nio.Buffer::limit (5 bytes) accessor @ 28 java.nio.ByteBuffer::array (35 bytes) inline (hot) @ 34 java.nio.ByteBuffer::arrayOffset (35 bytes) inline (hot) @ 38 java.nio.Buffer::position (5 bytes) accessor @ 45 java.nio.ByteBuffer::arrayOffset (35 bytes) inline (hot) @ 49 java.nio.Buffer::limit (5 bytes) accessor @ 67 java.lang.Math::min (11 bytes) (intrinsic) @ 482 sun.nio.cs.UTF_8::access$200 (8 bytes) inline (hot) @ 4 sun.nio.cs.UTF_8::updatePositions (23 bytes) inline (hot) @ 3 java.nio.CharBuffer::arrayOffset (35 bytes) inline (hot) @ 7 java.nio.Buffer::position (43 bytes) too big @ 14 java.nio.ByteBuffer::arrayOffset (35 bytes) inline (hot) @ 18 java.nio.Buffer::position (43 bytes) too big ** 137 9 b java.nio.Buffer::position (43 bytes)** 137 10 n java.lang.System::arraycopy (native) (static)** 139 11 b java.lang.Object::<init > (1 bytes)** 145 12 b java.nio.Buffer::limit (5 bytes)** 145 13 b java.nio.charset.CoderResult::isUnderflow (13 bytes)** 146 14 b java.io.BufferedWriter::ensureOpen (18 bytes)146 15 b java.io.PrintStream::ensureOpen (18 bytes)146 16 !b java.io.BufferedWriter::write (117 bytes) @ 9 java.io.BufferedWriter::ensureOpen (18 bytes) inline (hot) @ 42 java.io.BufferedWriter::min (9 bytes) inline (hot) @ 63 java.lang.String::getChars (62 bytes) inline (hot) @ 58 java.lang.System::arraycopy (0 bytes) (intrinsic) ** 156 17 s b java.io.BufferedOutputStream::flush (12 bytes) @ 1 java.io.BufferedOutputStream::flushBuffer (29 bytes) inline (hot) @ 20 java.io.FileOutputStream::write (12 bytes) inline (hot) \-> TypeProfile (4466 /4466 counts) = java/io/FileOutputStream @ 8 java.io.FileOutputStream::writeBytes (0 bytes) native method @ 8 java.io.OutputStream::flush (1 bytes) inline (hot) \-> TypeProfile (6700 /6700 counts) = java/io/FileOutputStream 157 18 b java.io.BufferedOutputStream::flushBuffer (29 bytes) @ 20 java.io.FileOutputStream::write (12 bytes) inline (hot) \-> TypeProfile (4466 /4466 counts) = java/io/FileOutputStream @ 8 java.io.FileOutputStream::writeBytes (0 bytes) native method ** 158 19 b java.io.OutputStream::flush (1 bytes)** 160 20 b java.lang.String::length (6 bytes)** 161 21 b java.nio.ByteBuffer::array (35 bytes)** 170 22 b java.nio.Buffer::limit (62 bytes)... ** 242 50 b java.lang.String::indexOf (7 bytes) @ 3 java.lang.String::indexOf (70 bytes) inline (hot) ** 245 51 b java.lang.String::valueOf (14 bytes) @ 10 java.lang.String::toString (2 bytes) inline (hot) \-> TypeProfile (6700 /6700 counts) = java/lang/String ** 246 52 b TestKt::hello (13 bytes) !m @ 9 java.io.PrintStream::println (31 bytes) inline (hot) @ 1 java.lang.String::valueOf (14 bytes) inline (hot) @ 10 java.lang.String::toString (2 bytes) inline (hot) @ 11 java.io.PrintStream::print (13 bytes) inline (hot) !m @ 9 java.io.PrintStream::write (83 bytes) inline (hot) @ 5 java.io.PrintStream::ensureOpen (18 bytes) inline (hot) @ 13 java.io.Writer::write (11 bytes) inline (hot) @ 4 java.lang.String::length (6 bytes) inline (hot) !m @ 7 java.io.BufferedWriter::write (117 bytes) already compiled into a big method !m @ 20 java.io.BufferedWriter::flushBuffer (53 bytes) already compiled into a big method @ 27 java.io.OutputStreamWriter::flushBuffer (8 bytes) already compiled into a big method @ 40 java.lang.String::indexOf (7 bytes) inline (hot) @ 3 java.lang.String::indexOf (70 bytes) inline (hot) !m @ 15 java.io.PrintStream::newLine (73 bytes) inline (hot) @ 5 java.io.PrintStream::ensureOpen (18 bytes) inline (hot) @ 12 java.io.BufferedWriter::newLine (9 bytes) inline (hot) @ 5 java.io.Writer::write (11 bytes) inline (hot) @ 4 java.lang.String::length (6 bytes) inline (hot) !m @ 7 java.io.BufferedWriter::write (117 bytes) already compiled into a big method !m @ 19 java.io.BufferedWriter::flushBuffer (53 bytes) already compiled into a big method @ 26 java.io.OutputStreamWriter::flushBuffer (8 bytes) already compiled into a big method s @ 40 java.io.BufferedOutputStream::flush (12 bytes) inline (hot) \-> TypeProfile (6700 /6700 counts) = java/io/BufferedOutputStream @ 1 java.io.BufferedOutputStream::flushBuffer (29 bytes) inline (hot) @ 20 java.io.FileOutputStream::write (12 bytes) inline (hot) \-> TypeProfile (4467 /4467 counts) = java/io/FileOutputStream @ 8 java.io.FileOutputStream::writeBytes (0 bytes) native method @ 8 java.io.OutputStream::flush (1 bytes) inline (hot) \-> TypeProfile (6701 /6701 counts) = java/io/FileOutputStream ... 269 57 b java.io.BufferedWriter::newLine (9 bytes) @ 5 java.io.Writer::write (11 bytes) inline (hot) @ 4 java.lang.String::length (6 bytes) inline (hot) !m @ 7 java.io.BufferedWriter::write (117 bytes) already compiled into a big method ** 279 58 % b TestKt::main @ 5 (20 bytes) @ 10 TestKt::hello (13 bytes) already compiled into a big method ** 493 58 % TestKt::main @ -2 (20 bytes) made not entrant
可以看 246 对应的这一行,这里 hello 方法下的调用均已被 inline 优化, 279 这里表示 hello 这个方法已经被编译到一个 big method 里了。注释里的数字表示中间打印了多少个println,可以看出在经过1w+的循环过程中, JIT 逐渐将这些写方法 inline + 编译成 native code。
具体这个 log 的条件可以参考下面的源码
1 2 3 4 5 6 7 8 9 10 if (!callee_method->force_inline()) { if (callee_method->has_compiled_code() && callee_method->instructions_size() > InlineSmallCode) { set_msg("already compiled into a big method" ); return true ; } }
4. Native Code
前面的 hello world 就会变成下面的样子(未开启分层编译,开了之后6k+行)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [Disassembling for mach='i386:x86-64 '] [Entry Point] [Constants] # {method} {0x0000000117b0a000 } 'hashCode' '() I' in 'java/lang/String' # [sp+0x30 ] ( sp of caller) 0x000000010b61de60 : mov 0x8 ( %rsi) ,%r10d 0x000000010b61de64 : shl $0x3 ,%r10 0x000000010b61de68 : cmp %r10,%rax 0x000000010b61de6b : jne 0x000000010b5f3e60 ; {runtime_call} 0x000000010b61de71 : data32 xchg %ax,%ax 0x000000010b61de74 : nopl 0x0 ( %rax,%rax,1 ) 0x000000010b61de7c : data32 data32 xchg %ax,%ax [Verified Entry Point] 0x000000010b61de80 : mov %eax,-0x14000 ( %rsp) 0x000000010b61de87 : push %rbp 0x000000010b61de88 : sub $0x20 ,%rsp ;*synchronization entry ; - java.lang.String::hashCode@-1 ( line 1466 ) ... // 1000 + lines
4.1 Too Much ASM 这里可以做一个对比,源代码只有 3 行,到字节码有不到20行,到 ASM 就 1000+ 行代码了,而且 C2 产生的代码量还会远高于 C1,大概是4倍左右的,因为 C2 做 Inline expansion 等优化。同时由于 C2 在编译优化的时候会 profiling ,会有更多的额外开销。
下面来看一个例子:
1 2 3 4 5 6 7 8 9 fun main () for (i in 0. .100000 ) { hello() } } private fun hello () Int { return 1 +1 }
其中 hello 的字节码如下,这里其实可以看出编译器还是比较聪明的,直接将 1+1的结果编译了出来,这样就不用加载两个 int 在做加法了。
1 2 3 4 5 6 7 8 private final static hello()I L0 LINENUMBER 8 L0 ICONST_2 IRETURN L1 MAXSTACK = 1 MAXLOCALS = 0
从 JIT 输出的 log 也可以看出,hello 这个方法最终被 inline 优化了
1 2 @ 14 java.lang.Math::min (11 bytes) (intrinsic) @ 10 TestKt::hello (2 bytes) inline (hot)
编译到的 ASM 如下,这里只截取了 Hello 部分的 ASM 其他的过长了就不在这里展示了,注释部分橙色的为自己写的注释其他的是 JVM 生成的:
1 2 3 4 5 6 7 8 9 10 11 12 13 [Constants] # {method} {0x0000000115d59b48 } 'hello' '() I' in 'TestKt' # [sp+0x20 ] ( sp of caller) 0x00000001094728c0 : sub $0x18 ,%rsp ; 给栈帧分配空间 0x00000001094728c7 : mov %rbp,0x10 ( %rsp) ;*synchronization entry ; - TestKt::hello@-1 ( line 8 ) 0x00000001094728cc : mov $0x2 ,%eax ; 这里的 0x2 就是刚刚 hello 里计算的结果,这里直接吧 2 放入了 eax 寄存器 0x00000001094728d1 : add $0x10 ,%rsp 0x00000001094728d5 : pop %rbp 0x00000001094728d6 : test %eax,-0x1e558dc ( %rip) # 0x000000010761d000 ; {poll_return} 0x00000001094728dc : retq ; return
上面汇编的信息带有一些额外东西,例如注释(ASM中注释是 ; ),内存地址,寄存器地址,各种 16 进制等。
4.2 NativeStack 为了更好的理解后面的内容,这里介绍一下 Native Stack。这个 native stack 是内存中的一段空间,大小依赖于操作系统和程序自身的配置,每个线程会有一个自己的栈。
在调用方法时,cpu 需要存放方法、参数、变量、返回值等东西,这些就是靠这个 native stack 完成的,一个简单的流程是压栈(push)参数的,然后压栈栈帧,然后出栈(pop)栈帧方法结束。我们使用上面例子中的 main 方法来解释这个过程。
下面是原始的 main 方法汇编结果,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 [Constants] # {method} {0x0000000115d59a10 } 'main' '() V' in 'TestKt' 0x00000001094740e0 : callq 0x0000000106ab3e6c ; {runtime_call} 0x00000001094740e5 : data32 data32 nopw 0x0 ( %rax,%rax,1 ) 0x00000001094740f0 : mov %eax,-0x14000 ( %rsp) ; 所有方法开始都会有的 mov push sub 0x00000001094740f7 : push %rbp ; 主要作用就是加载参数,push stack frame 0x00000001094740f8 : sub $0x20 ,%rsp ; 0x00000001094740fc : mov ( %rsi) ,%r13d 0x00000001094740ff : mov 0x8 ( %rsi) ,%ebx 0x0000000109474102 : mov %rsi,%rdi 0x0000000109474105 : movabs $0x106b12eaa ,%r10 0x000000010947410f : callq *%r10 ;*iload_0 ; - TestKt::main@5 ( line 2 ) 0x0000000109474112 : cmp %r13d,%ebx ; kotlin 的 for 循环这里不会放一个 $0x186a0 ,但是 while 会,比较神奇 0x0000000109474115 : jg 0x000000010947412d ;*if_icmpgt ; - TestKt::main@7 ( line 2 ) 0x0000000109474117 : nopw 0x0 ( %rax,%rax,1 ) ; 64 位 0x0000000109474120 : inc %ebx ; OopMap{off=66 } ;*goto ; - TestKt::main@17 ( line 2 ) 0x0000000109474122 : test %eax,-0x1e57128 ( %rip) # 0x000000010761d000 ;*goto ; - TestKt::main@17 ( line 2 ) ; {poll} 0x0000000109474128 : cmp %r13d,%ebx 0x000000010947412b : jle 0x0000000109474120 ;*if_icmpgt ; - TestKt::main@7 ( line 2 ) 0x000000010947412d : mov $0xffffff65 ,%esi 0x0000000109474132 : mov %ebx,0x4 ( %rsp) 0x0000000109474136 : mov %r13d,0x8 ( %rsp) 0x000000010947413b : callq 0x00000001094456a0 ; OopMap{off=96 } ;*if_icmpgt ; - TestKt::main@7 ( line 2 ) ; {runtime_call} 0x0000000109474140 : callq 0x0000000106ab3e6c ;*goto ; - TestKt::main@17 ( line 2 ) ; {runtime_call}
1 2 3 4 5 6 7 8 9 1 : push %rbp ; 所有方法开始都会有的 mov push sub,主要作用就是加载参数,push stack frame2 : cmp $0x186a0 ,%ebx ; kotlin 的 for 循环这里不会放一个 $0x186a0 ,但是 while 会,比较神奇3 : jg 7 4 : nopw 0x0 ( %rax,%rax,1 ) 5 : inc %ebx ; +1 6 : cmp %r13d,%ebx7 : jle 5 8 : retq $0xffffff65 ,%esi
1 2 3 4 5 6 7 8 9 10 11 12 # {method} {0x000000011cc1abe8 } 'tiny' '() I' in 'TestKt' # [sp+0x20 ] ( sp of caller) 0x00000001100208c0 : sub $0x18 ,%rsp 0x00000001100208c7 : mov %rbp,0x10 ( %rsp) ;*synchronization entry ; - TestKt::tiny@-1 ( line 8 ) 0x00000001100208cc : mov $0x2 ,%eax ; 1 +1 =2 0x00000001100208d1 : add $0x10 ,%rsp 0x00000001100208d5 : pop %rbp 0x00000001100208d6 : test %eax,-0x711a8dc ( %rip) # 0x0000000108f06000 ; safepoint ; {poll_return} 0x00000001100208dc : retq
1 2 3 4 # {method} {0x000000011cc1abe8 } 'tiny' '() I' in 'TestKt' # [sp+0x20 ] ( sp of caller) 0x00000001100208cc : mov $0x2 ,%eax ; 1 +1 =2 0x00000001100208dc : retq
4.3 SafePoint 当 JVM 中的所有线程都达到 SafePoint 的时候就会触发 gc,JVM会在分配内存与代码块结束的位置插入SafePoint
4.4 OSR(On-Stack Replacement) OSR 有些复杂,具体可以看R大的一个知乎回答
5. So What
can’t be modify
编译期优化(inlines constants)
但是下面这种情况就有些无能为力了
可重入锁
not pre-init a volatile object
因为这样asm会加一个锁
branch 跳转一个是O(1)的时间一个是二分查找O(logn)
涉及到两个指令 tableswitch、lookupswitch
特例string switch,主要是hash之后再equal的开销
最终关系到hashtable的表的大小,这个表的大小对 JIT 优化有些影响
主要是invokedynamic这个指令,涉及到动态创建 class 的问题
有的写法可以使 JIT 去 inline lambda 方法体,但是大多数时候 JIT 是无法优化的
6. Reference 深入理解Java即时编译器(JIT)-上篇
深入理解Java即时编译器(JIT)-下篇
小师妹学JVM之:JIT中的PrintCompilation
From Java to Assembly Down the Rabbit Hole (Charles Oliver Nutter, Red Hat)
jdk8u/jdk8u/hotspot: 2b2511bd3cc8 src/share/vm/runtime/advancedThresholdPolicy.hpp
What’s this new column in -XX:+PrintCompilation output?
ART是如何保证checkpoint 点一定会被跑到的?
OSR(On-Stack Replacement)是怎样的机制?
深入浅出 JIT 编译器
Understanding How Graal Works - a Java JIT Compiler Written in Java
JVM进阶 – 浅谈即时编译